Lokale KI-Workflows mit n8n - Zwischen Hype und Realität
Lokale KI klingt perfekt - aber funktioniert die Integration mit N8N wirklich? Ein ehrlicher Blick auf Tools und ihre Grenzen.
Lokale KI ist das neue Buzzword. Jeder will seine Daten behalten, niemand möchte mehr für OpenAI zahlen. Qwen-Modelle marschieren auf den Leaderboards nach oben, ComfyUI verspricht kreative Freiheit, und n8n soll alles zusammenbringen. Soweit die Theorie.
Die Realität? Nuancierter als YouTube-Tutorials vermuten lassen.
Was lokale KI wirklich bedeutet
Lokale KI teilt sich in zwei Hauptbereiche: Large Language Models (LLMs) für Text und Code, sowie Diffusion-Modelle für kreative Inhalte. Die Grundidee ist bestechend einfach: Statt deine Prompts an OpenAI zu schicken, läuft alles auf deinem Rechner.
Die Frage ist nur: Funktioniert das auch praktisch?

LM Studio: Der pragmatische Ansatz
LM Studio (aktuell Version 0.3.32) hat sich als de-facto Standard für lokale LLMs etabliert. Die Software bietet eine ChatGPT-ähnliche Oberfläche und macht das Experimentieren mit verschiedenen Modellen zugänglich.
Aber seien wir ehrlich: Die Benutzerfreundlichkeit hat ihren Preis. Du lädst Modelle im GGUF-Format herunter, die bereits quantisiert sind. Q4 bedeutet 4-Bit-Präzision, Q8 bedeutet 8-Bit. Je kleiner die Zahl, desto kompakter das Modell - und desto schlechter die Qualität.
Die Faustregeln sind simpel, aber wichtig:
- GPU-VRAM muss größer sein als die Modellgröße
- Ein 4B-Parameter-Modell braucht etwa 3-4 GB VRAM
- Größere Modelle teilen sich zwischen GPU und CPU auf
Die Qwen-Realität
Qwen 3 VL mit 4 Milliarden Parametern ist tatsächlich beeindruckend für seine Größe. Vision und Language in einem kompakten Paket. Aber vergleichen wir das mal mit GPT-4: Eine Billion Parameter gegen 4 Milliarden. Das ist wie ein Käfer gegen einen Elefanten.
Trotzdem: Für viele Anwendungsfälle reichen die kleineren Modelle aus. OCR funktioniert gut, einfache Programmieraufgaben klappen, Textzusammenfassungen sind okay. Nur erwarte keine Wunder.
ComfyUI: Kreativität mit Kompromissen
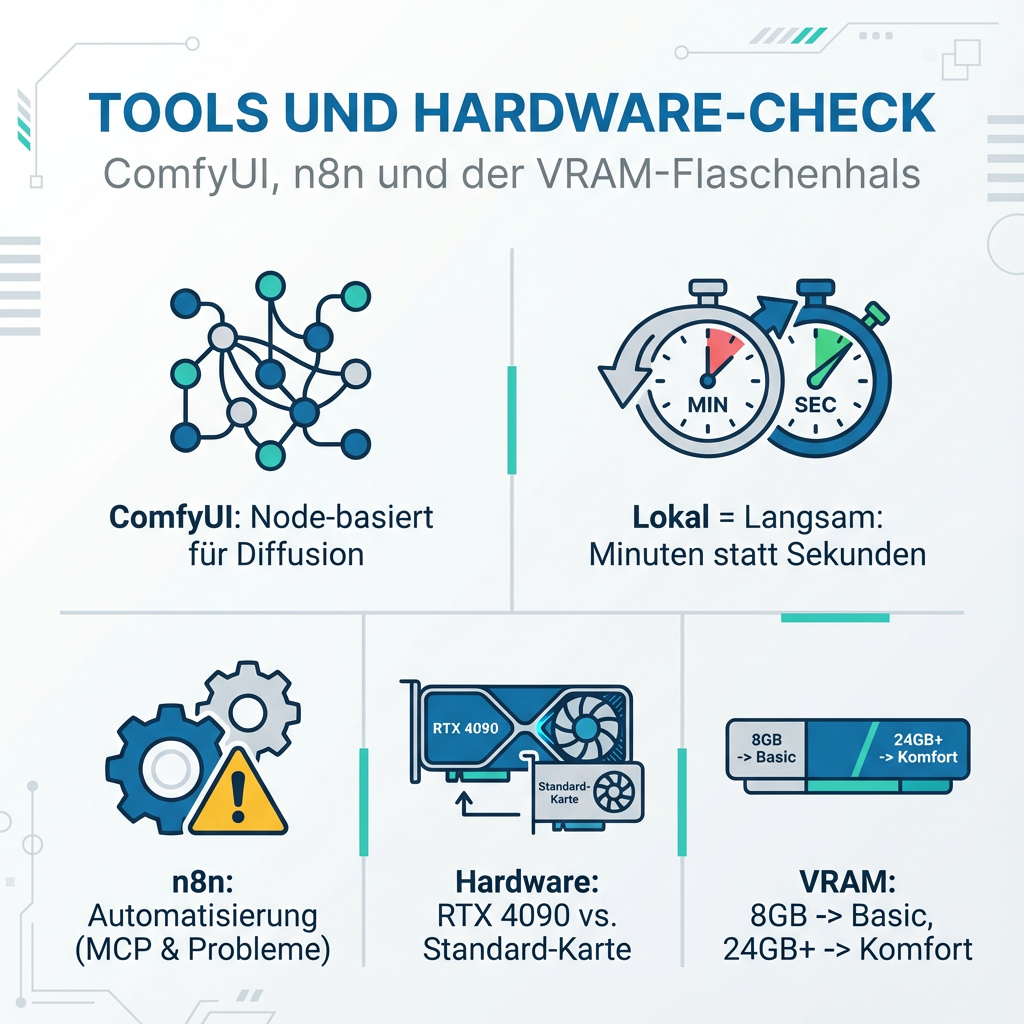
ComfyUI ist das Node-basierte Interface für Diffusion-Modelle. Optisch verwirrend für Einsteiger, aber mächtig wenn man es beherrscht. Die Workflows sehen aus wie Spaghetti-Code, funktionieren aber überraschend gut.
Das Problem liegt weniger bei ComfyUI selbst, sondern bei den Erwartungen. Stable Diffusion XL braucht mindestens 6-8 GB VRAM für vernünftige Ergebnisse. Die meisten Consumer-Grafikkarten schaffen das gerade so.
Und dann ist da noch die Geschwindigkeit. Was in Midjourney Sekunden dauert, braucht lokal Minuten. Besonders bei komplexeren Workflows mit mehreren Sampling-Schritten.
n8n als Kleber: Funktioniert, aber...
Hier wird es interessant. n8n kann theoretisch alles verbinden: LM Studio über dessen lokale API, ComfyUI über dessen JSON-Export, und dazu noch E-Mail, Datenbanken, whatever.
Das Model Context Protocol (MCP) ist der neue Standard für diese Integration. Entwickelt von Anthropic, soll es KI-Modelle mit externen Tools verbinden. In der Praxis bedeutet das: Du kannst aus LM Studio heraus n8n-Workflows triggern.
Aber hier beginnen die Probleme:
-
Setup-Komplexität: Die Integration erfordert JSON-Configs, URL-Mappings und Debug-Sessions. Nicht gerade benutzerfreundlich.
-
Fehleranfälligkeit: Ein falsches Mapping, und dein Workflow schickt "undefined" statt deines Prompts an ComfyUI.
-
Performance-Overhead: Jeder Hop zwischen Tools kostet Zeit. Was direkt in ChatGPT 2 Sekunden dauert, braucht über mehrere lokale Services deutlich länger.
Die Hardware-Realität
Sprechen wir über den Elefanten im Raum: Hardware. Die meisten YouTube-Demos laufen auf RTX 4090 oder ähnlich teuren Karten. Mit einer GTX 1660 oder RTX 3060 sieht die Welt anders aus.
Realitätscheck für Consumer-Hardware:
- 8GB VRAM: Qwen 7B oder Llama 7B, kleine Diffusion-Modelle
- 12GB VRAM: Größere Sprachmodelle, Stable Diffusion XL okay
- 16GB VRAM: Komfortabler Bereich für die meisten Workflows
- 24GB+ VRAM: Hier wird es erst richtig interessant
Das Kimika K2 Modell mit einer Billion Parametern braucht 646 GB RAM für Q4-Quantisierung. Das hat praktisch niemand zu Hause.
Was funktioniert wirklich gut
Trotz aller Kritik: Es gibt Use Cases, wo lokale KI brilliert.
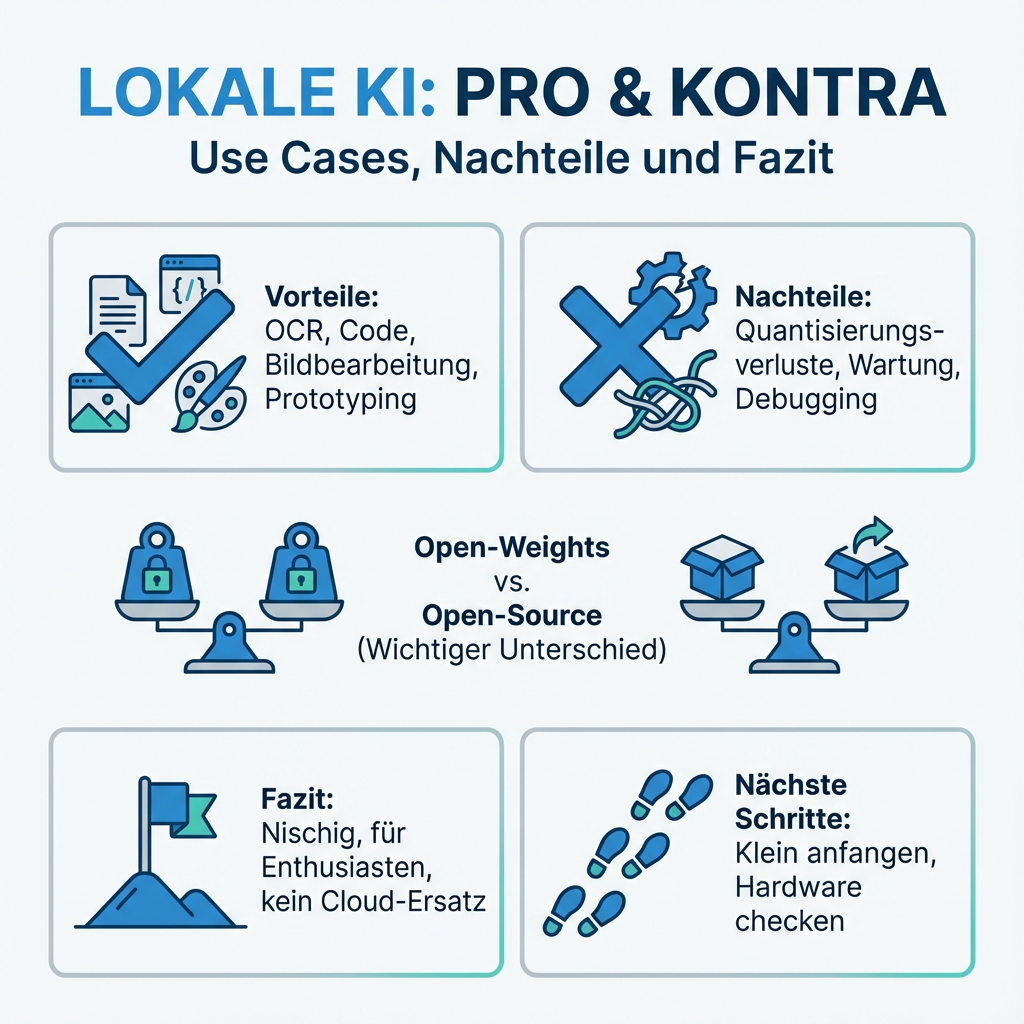
OCR und Dokumentenverarbeitung: Qwen VL macht bei Rechnungen und PDFs einen soliden Job. Datenschutz inklusive.
Code-Generierung: Kleinere Programmieraufgaben lösen auch 7B-Modelle zuverlässig. Für Boilerplate-Code völlig ausreichend.
Bildbearbeitung: ComfyUI mit spezialisierten Workflows kann beeindruckende Ergebnisse liefern. Wenn man die Zeit investiert.
Prototyping: Für Experimente und Proof-of-Concepts sind lokale Setups perfekt. Keine API-Limits, keine Kosten.
Die ungeschönten Nachteile
Quantisierungsverluste: Q4-Modelle sind messbar schlechter als ihre FP16-Originale. Bei komplexen Reasoning-Aufgaben wird das deutlich spürbar.
Maintenance-Overhead: Updates für LM Studio, neue Modelle, ComfyUI-Plugins, N8N-Nodes. Das Setup will gepflegt werden.
Geschwindigkeit: Lokale Inferenz ist langsamer als Cloud-APIs. Besonders bei größeren Modellen und komplexeren Tasks.
Debugging-Hölle: Wenn etwas nicht funktioniert, ist die Fehlersuche mühsam. Logs in LM Studio, Execution-Details in N8N, ComfyUI-Konsole - alles separat.
Open-Weights vs. Open-Source: Ein wichtiger Unterschied
Viele der "Open-Source"-Modelle sind eigentlich nur Open-Weights. Du bekommst die Parameter, aber nicht den Trainingscode oder die Daten. Llama, Qwen, Mistral - alle fallen in diese Kategorie.
Echtes Open-Source wäre transparenter, aber auch aufwendiger zu nutzen. Für die meisten Anwendungsfälle ist Open-Weights ausreichend.
Fazit: Nützlich, aber nischig
Lokale KI mit N8N-Integration ist machbar und für spezielle Anwendungsfälle durchaus sinnvoll. Besonders wenn Datenschutz wichtig ist oder man sich von API-Abhängigkeiten lösen möchte.
Aber es ist kein Drop-in-Replacement für Cloud-Services. Die Setup-Komplexität, Hardware-Anforderungen und Performance-Unterschiede sind real. Wer erwartet, ChatGPT 1:1 nachzubauen, wird enttäuscht.
Die Tools werden besser, die Modelle leistungsfähiger. Aber aktuell ist lokale KI eher etwas für Enthusiasten und spezielle Use Cases als für Mainstream-Anwendungen.
Die Entscheidung sollte pragmatisch fallen: Wenn du die Hardware hast, die Zeit investieren willst und echte Vorteile bei Datenschutz oder Kosten siehst - go for it. Ansonsten sind Cloud-APIs oft der einfachere Weg.
Nächste Schritte für Interessierte:
- Klein anfangen: LM Studio mit einem 7B-Modell testen
- Hardware prüfen: VRAM messen, realistische Erwartungen setzen
- Use Case definieren: Wo bringt lokal wirklich Vorteile?
- Schrittweise erweitern: Erst lokale KI verstehen, dann Automatisierung